| home ~ Sembase history ~ concept ~ design ~ semitic languages ~ Sembase applications |

| home ~ Sembase history ~ concept ~ design ~ semitic languages ~ Sembase applications |
| Application Aiding Design |
|
It is too soon now to begin using the database for general research. But it is necessary to use it for database design/data entry. By sorting on various orders of C1, C2 and C3, it will be possible to identify very nearly all Minimal Root Pairs (MRPs: root pairs with identical or very similar meaning, two consonants the same, and no metathesis). These pairs are so numerous that they often form clusters (MRCs or Minimal Root Clusters—MRC). A field will also be used to indicate if a root is a member of an MRC. Actually, the definition of "cluster" may be drawn less strictly (see ERCs below). The effort to identify MRPs was suspended when the construction of the database was undertake, to concentrate on data entry. But even just using the note cards, over 2,200 had been identified for Arabic alone.
At that time a preliminary analysis of MRPs was undertaken. They were entered into a matrix to determine their distribution relative to their point of articulation in the oral cavity. The matrix consisted of one column and one row for every Arabic consonant, arranged in the order of proximity in the oral cavity. Initially this order was simply a best-effort guess. The diagonal of the matrix was the intersect of each consonant with itself. Since this is not interesting, the diagonal was thrown out. Each cell above the diagonal has a corresponding cell below it. These two cells are intersects of the same two consonants, but in different order. Since the order (i.e., the direction of a possible sound shift) is not known, the cells above the diagonal were also thrown out. The remaining cells comprise one cell for each pair of consonants. The matrix looks like this:
|

|
|
The following image shows how MRPs are entered into the matrix. This is the cell where G-dot (ghayn) and H-breve (kha') intersect in the matrix. MRPs that are the same except that one has ghayn and the other kha' are entered in this cell. All other MRPs are entered in the matrix in their corresponding cell in this manner.
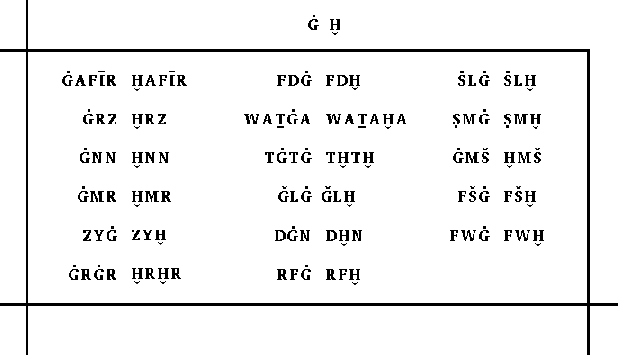
This matrix is useful in several respects. First, it identifies information to be entered in the database for each root that appears in the matrix. Second, since MRPs are defined as stringently as possible, there is a presumption of relationship. One test of this is to examine their distribution in the matrix. To the extent that they are the result of sound shifts among related roots, they will cluster close to the diagonal. To the extent that they are accidental, they will distribute randomly throughout the cells. A mathematical measurement is possible, as well as an estimate of probability. So far they cluster very close to the diagonal. When the Arabic portion of the analysis is completed, there will be over 3,000 MRPs in the Arabic matrix. The relative number in each cell is also interesting. It is the closest thing to an empirical statement of the relative frequency of various possible sound shifts (and hence the probability?). We must bear in mind of course that no single pair has been demonstrated independently to be cognate. Furthermore, many cases of actual sound shifts among cognates would represent multiple shifts. For example, although m and h are not thought of as a probable sound shift, th > s > h is possible, as well as th > f > m. If an etymological root went through the first shift series in one language, and the second series in another, the result would be a pair of cognate roots with "m" corresponding to "h". In any case, it will be interesting to analyze this body of data when assembled.
Changing the order of the consonants, i.e., the order of the rows and columns, changes the degree of clustering along the diagonal. The order that produces the tightest cluster along the diagonal will be adopted for the sort order of characters in the font for for entering roots into the "Phon." field. Initially a best-effort guess, the order will be adjusted to produce the maximum clustering along the diagonal. This is the order that will result from sorts on the "Phon." field, to facilitate efforts by visual inspection to identify roots that may be cognate.
Minimal Metathesis Pairs (MMPs) are also identified. They are roots with the same or nearly same meaning, and the same consonants, but in different order. If an MMP has both meaning and two consonants in common with a member of an MRC, it is included in it. When one member of an MMP falls within one MRC, and the other falls within another MRC, it links the two.
There is some unavoidable element of subjectivity in the determination that two roots have "identical or nearly identical" meaning. Hopefully users will find that this subjective element is minimal. On the other hand, scholars at times conclude that roots are cognate when meaning is nearly identical and two consonants are the same, even if there is metathesis, or when only one consonant is the same. An MRC can be expanded by the inclusion of such a root. It may be that a suspicion of relationship is strengthened by the configuration of members of the MRC. When MRCs are thus expanded, they are referred to as ERCs (Extended Root Clusters).
Semitists have long been frustrated by the fact that the methods used in Indo-European linguistics have not produced comparable results when applied to the Semitic languages. Hopefully a systematic and relatively exhaustive identification of MRPs, MRCs, MMPs and ERPs will prove to be a productive complement to that approach.
|